Friday 15 April 2016
Leveraging Modern Filesystems In rr
During recording, rr needs to make sure that the data read by all mmap and read calls is saved to the trace so it can be reproduced during replay. For I/O-intensive applications (e.g. file copying) this can be expensive in time, because we have to copy the data to the trace file and we also compress it, and in space, because the data is being duplicated.
Modern filesystems such Btrfs and XFS have features that make this much better: the ability to clone files and parts of files. These cloned files or blocks have copy-on-write semantics: i.e. the underlying storage is shared until one of the copies is written to. In common cases no future writes happen or they happen later when copying isn't a performance bottleneck. So I've extended rr to support these features.
mmap was pretty easy to handle. We already supported hardlinking mmapped files into the trace directory as a kind of hacky/incomplete copy-on-write approximation, so I just extended that code to try BTRFS_IOC_CLONE first. Works great.
read was harder to handle. We extend syscall buffering to give each thread its own "cloned-data" trace file, and every time a large block-aligned read occurs, we first try to clone those blocks from the source file descriptor into that trace file. If that works, we then read the data for real but don't save it to the syscall buffer. During replay, we read the data from the cloned-data trace file instead of the original file descriptor. The details are a bit tricky because we have to execute the same code during recording as replay.
This approach introduces a race: if some process writes to the input file between the tracee cloning the blocks and actually reading from the file, the data read during replay will not match what was read during recording. I think this is not a big deal since in Linux such read/write races can result in the reader seeing an arbitrary mix of old and new data, i.e. this is almost certainly a severe bug in the application, and I suspect such bugs are relatively rare. Personally I've never seen one. We could eliminate the race by reading from the cloned-data file instead of the original input file, but that performs very poorly because it defeats the kernel's readahead optimizations.
Naturally this optimization only works if you have the right sort of filesystem and the trace and the input files are on the same filesystem. So I'm formatting each of my machines with a single large btrfs partition.
Here are some results doing "cp -a" of an 827MB Samba repository, on my laptop with SSD:
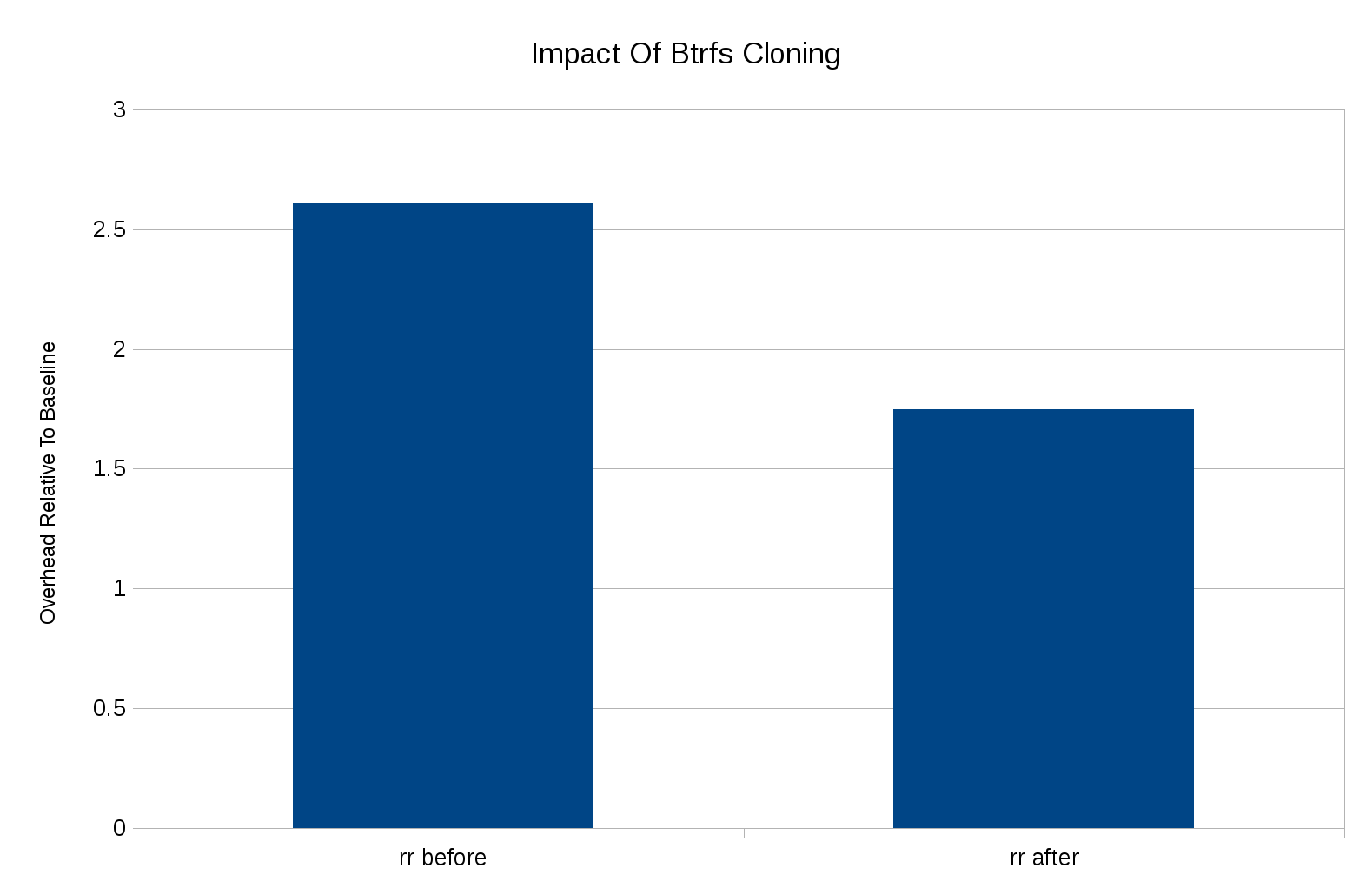
The space savings are even better:
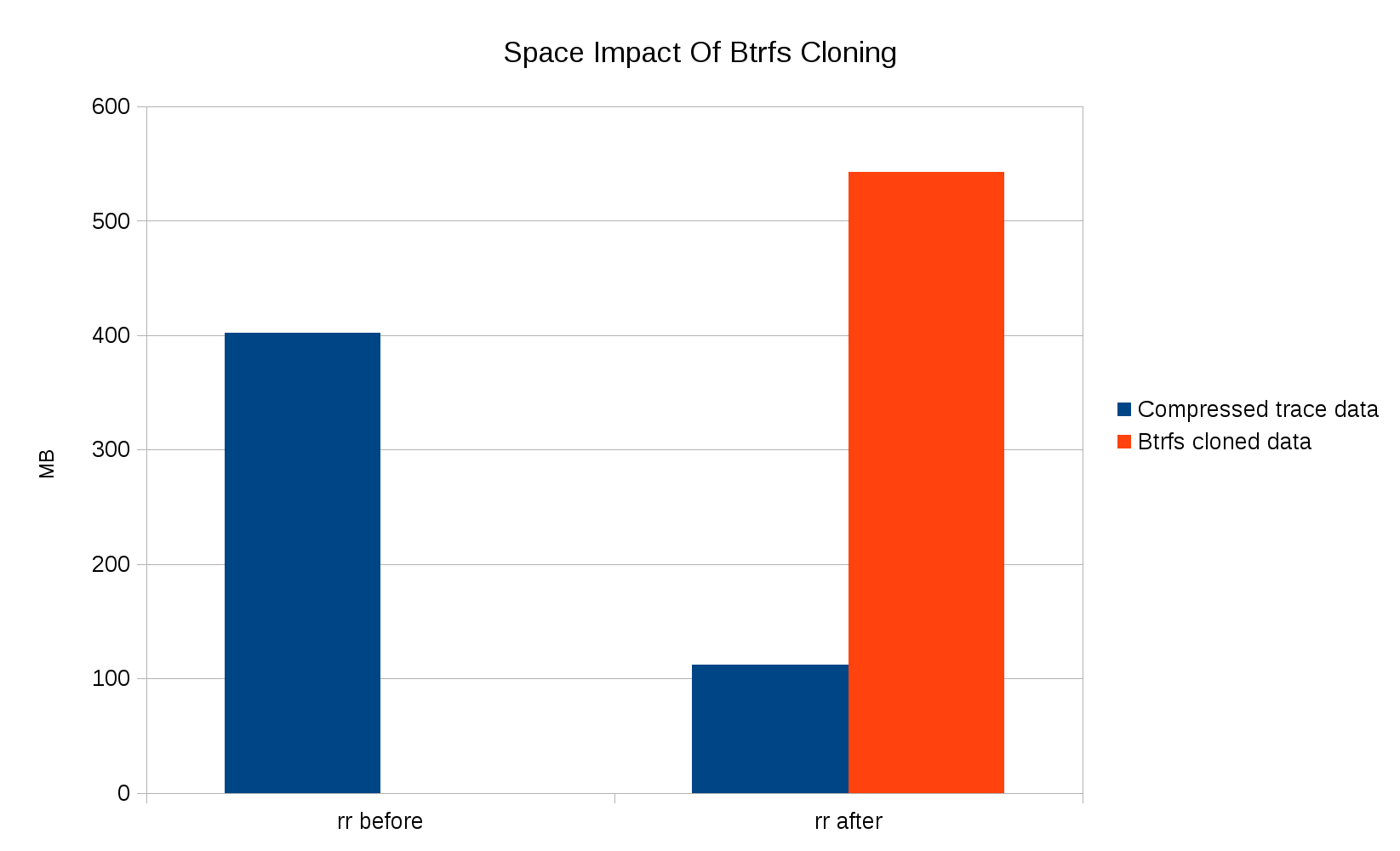 The cloned btrfs data is not actually using any space until the contents of the original Samba directory are modified. And of course, if you make multiple recordings they continue to share space even after the original files are modified. Note that some data is still being recorded (and compressed) normally, since for simplicity the cloning optimization doesn't apply to small reads or reads that are cut short by end-of-file.
The cloned btrfs data is not actually using any space until the contents of the original Samba directory are modified. And of course, if you make multiple recordings they continue to share space even after the original files are modified. Note that some data is still being recorded (and compressed) normally, since for simplicity the cloning optimization doesn't apply to small reads or reads that are cut short by end-of-file.